Accessibility 2: Engaging Multiple Senses
My analysis of ASL music videos as accessible multimodal compositions builds on the argument that Stephanie Kerschbaum (2013) developed for bringing our attention to the design of digital and multimodal compositions. Kerschbaum has considered the implications of multimodal texts in which one of the digital modes of representation is rendered inaccessible for a certain population of users. She underscored the distinction between how multimodality celebrates the use of multiple modes, and how one or more of the modes in many multimodal compositions are rendered inaccessible to certain users.
As I have discussed, uncaptioned videos convey verbal meaning primarily through the aural mode and exclude audiences who cannot access the aural content. These non-subtitled videos create what Kerschbaum called an inhospitable multimodal environment.
Multimodal inhospitality counters the belief that, as Kerschbaum (2013) wrote, “multimodality is valuable because of the way it engages multiple senses at once, thus immersing users more fully in an environment or amplifying the communicative resources of a text” when they juxtapose modes (Commensurability section, para. 4). Multimodal texts are expected to generate a synergy of modes in which users can absorb the message through combined visual and aural stimulation. However, when designers create multimodal texts with generic audience members in mind—those who can process every component of the composition perfectly—they may be more likely to use each mode for different purposes. In uncaptioned music videos, for instance, the lyrics can only be accessed through hearing the music—and these videos are inhospitable multimodal environments.
Kerschbaum (2013) called on us to “consider how information embedded within multimodal texts and environments can be made available through multiple channels” and how we can “generate multiple, even redundant, ways of representing and communicating that information” across modes to ensure that audience members can access the information (Design: Implications and Recommendations section, para. 1). Kerschbaum emphasized the design of multimodal texts with attention to deliberate choices of accessible modes. For instance, instead of including transcripts to the bottom of videos as a retrofit, accurate subtitles should be incorporated within videos during the design process.
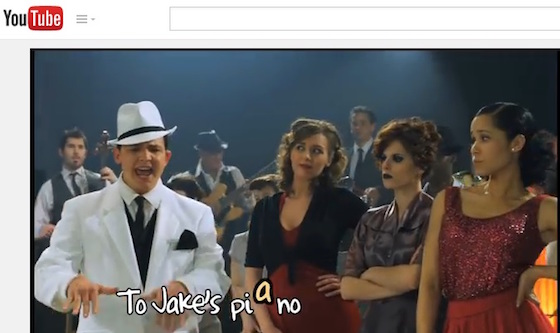
Figure 7: Screenshot from Sean Forbes’ (2011) video, “Sean Forbes ‘Let’s Mambo’ Ft. Marlee Matlin”
Designers of ASL music videos engage in accessible multimodal practices since they do not replace one mode (sound) with another (visual text), but instead synchronize multiple modes to reach those who can hear and those who do not hear the music. In Sean Forbes (2011), “Sean Forbes ‘Let’s Mambo’ Ft. Marlee Matlin” (see Figure 7 above), the visual text moves in tandem with the beat of the music and the lyrical syllables, as in piano. Although these videos are not fully accessible compositions, we can use these pieces to encourage our students to synchronize meaning through all the modes in their composition.
Analyzing ASL music videos can help our students design their own rhetorical practices for communicating to other audience members, including those who cannot process the visual mode. In this way ASL music videos become not ideal models, but as points of critique. Let’s turn to the next example, Sean Berdy’s (2012) music video, “Enrique Iglesias’s Hero in American Sign Language [Sean Berdy],” which made the thematic meaning of love accessible through the synchronization of aural, visual, spatial, and gestural modes.
NEXT: Example #3: "Hero"