Design Principles
Page Contents
Built in Drupal 7, the Writing Studies Tree (WST) takes advantage of that platform’s native node architecture to store information about individual people or institutions, and employs Drupal's Relation module to build information-rich links between them: degrees granted, committee memberships, even stories about how people met. A custom module written for the WST adds a number of interactive visualizations, using the D3 JavaScript library, in order to present the relationships in a variety of ways.
Users can search and view the WST data through three distinct visualizations: the Individual view, the Family Tree view, and the Full Network view. Users can also add labels through two open taxonomies, allowing navigation by areas of interest or by affiliation with professional organizations. In a significant shift from prior academic genealogies, the WST also provides space for both open-ended narrative contributions and a data structure of nodes and relations, so as to build navigable paths that follow the interpersonal and inter-institutional relationships.
We planned the architecture of the WST based on how we imagined people might use the site and have reflected on and reconsidered this architecture as actual use-cases evolve (see “Users and Uses”). In this section we explain our design choices and principles. Some of these designs are already achieved and implemented, while others are works in progress.1We welcome feedback and value your input: if you have suggestions for features or are interested in helping us further develop the site, please contact us at admin@writingstudiestree.org.
Participatory Design: Trust in the Users
The Writing Studies Tree enables both local experts, who have extensive knowledge of their own personal and institutional histories, and other writing studies researchers to contribute information in a way that allows the data to be aggregated, networked, and visualized.
Moreover, by crowdsourcing disciplinary self-study and trusting site members to curate the archive, the WST invites users of all levels, from undergraduates to senior faculty, to see themselves as members of an evolving network of scholars who contribute to the collective project of knowledge-making within the field. Anyone can contribute and update information, so the WST becomes a “participatory archive” (Huvila, 2008). In the words of Isto Huvila (2008), “The principal implication of assuming the notion of a participatory archive is the reconfiguration of responsibilities between curators, users and the general public. As the number of participants and of voices increases in the records management process, this broadens the relevant context of the records” (p. 33). That is, the more people who participate, the more reasons there are for other members of their local and disciplinary communities to participate.
Anyone can contribute
It does not matter if you are a first-year student in a writing-about-writing course or a retired professor: It is the ethos of the WST to trust users to add and edit information collectively in order to achieve a more accurate representation of the field. Crowdsourcing the WST in this way increases the collective knowledge represented in its data, far more than only a small group of dedicated data entry consultants could produce.
Of course, the commitment to crowdsourcing our data also presents certain challenges, which are mostly the result of human error. Because of variation in conventions for naming/spelling people and institutions, inadvertent duplicate or partial entries may find their way into the WST. Currently, these need to be corrected manually, though we are working towards a mechanized process to automatically identify and merge duplicates. As is the case with any open folksonomy, we also have tags that are only used once, or variations on the same tag that are difficult to merge. Additionally, there is always the risk of inaccurate or incomplete data, but the WST’s use of stored and restorable revision histories mitigate the risk of vandalism, and page “watching” (email alerts when something changes on specific pages you select) is a planned feature for the future.
Rapid input
In order to encourage users at every level to participate, we have included simple input forms that direct the user through the process of adding information. Based on our experience working with new users at workshops and conferences, we have found that most users are able to create an account, add a page for themselves as a Person in the WST, and add a new relationship with an institution or colleague quickly. The input fields have auto-complete enabled to help prevent the aforementioned duplication and variation issues when inputting names and tags. Adding further relations or pages takes less time, particularly with information ready-at-hand, and we made several of the fields optional for those who do not recall dates or who do not have access to the citation information they wish to add.
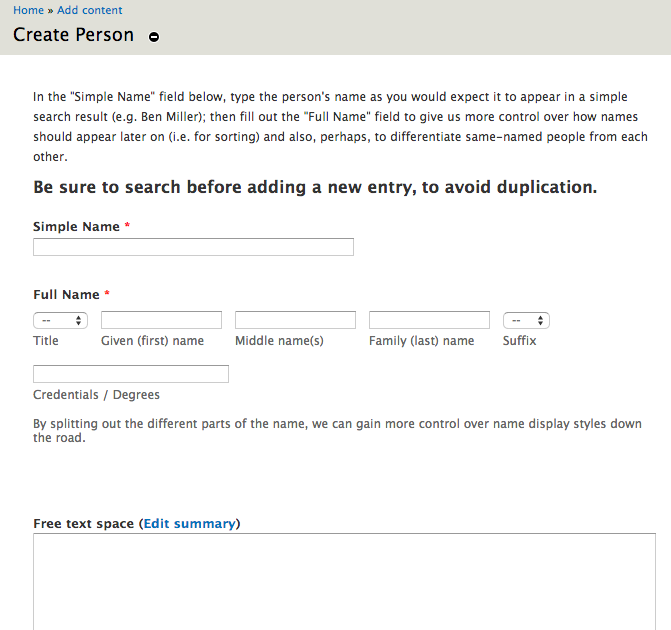
This commitment to rapid input, however, has led to problematic gaps in our metadata, making additional visualizations—such as a timeline or cohort views for individuals and schools—much more challenging. In “Modeling Rhetorical Disciplinarity: Factor-Mapping the Digital Network,” Nathan Johnson (2015b) suggests that at least some of the data the WST is missing exists in usable form in places like Acknowledgements sections of dissertations, and we hope to scrape these sources in the future. In the meantime, the WST offers a way around one challenge that Johnson faced, which was determining which schools’ dissertations and graduates to research when studying writing studies: rather than trying to pre-determine who counts as “in” writing studies, the WST allows people to self-identify and add their own institutional affiliations, making it easier to narrow the search and reduce consequent workload when following up on things like job placement statistics.
In the course of workshopping the site with our users at conferences, we gained valuable input on how to improve the clarity of our guidance for these forms, and we are working to incorporate these suggestions into future site redesign/revisions.2Our first step was to create a screencapture walkthrough of the demonstration and guidance we would otherwise give in person, available through the Help page of the WST site. For example, one promising direction that has emerged from user suggestions is to link outward from entries in the WST to relevant pages within projects located elsewhere, such as the Digital Archive of Literacy Narratives (DALN) or the recently proposed WPA Story Project.3A recent source of inward links to WST entries comes from the Kairos ScholarNames wiki, and we hope to provide corresponding links back to the wiki in the near future. When shared or linked to in the WST, these stories become more discoverable, because the network links and family trees provide new, (inter)personally motivated paths along which users can browse to find them.
We have discovered through this process that our existing “links and citations” field is insufficiently structured for archival researchers, who may desire to locate more precisely the provenance of certain information as embedded in specific sources, and for the purpose of comparing citations to account for discrepancies among sources. The MetaData Mapping Project (n.d.), currently in development, offers one possible way of tracking “a series of fluctuating (non-static) relationships between physical agents – such as documents and their references – and conceptual activities – such as researchers’ motives and queries – all operating within the same domain” (Data Model and API, para. 2). We look forward to seeing more outcomes from that project, and will look for ways to apply their insights to the WST.
Rapid output
The WST immediately translates data inputted from users into publicly accessible and aggregated information, automatically updating the full range of network visualizations implemented on the site. This is not without cost: With the enthusiastic growth of the database comes a compensatory slowdown in rendering the complex Full Network visualization. However, we believe it is important to validate and welcome new users and their contributed knowledge, rather than cache the graph and introduce a delay. As the site continues to develop, we are seeking faster algorithms that will enable users to more immediately locate the impact of their recent contributions and how this new data changes our understanding of the field as a whole.
Structured Data: A Grammar of Relationships
In order to create flexible, aggregable, and scalable data for exploration and analysis, we provide a fixed but robust structure of node types and relationships. The full list of node and relation types and subtypes is shown in Table 1 below, with a discussion of our rationale for these types following the table.
Every relationship in the WST has at least three required components: two node “endpoints” and a relationship “edge” between them. To make this relation easier to grasp — and more centered on human experience — we stipulate that the relationship form a single grammatical sentence. For example, we might write that “Sondra Perl was mentored by Gordon Pradl.” Here, the first endpoint is Sondra Perl; she acts as the subject of the verb. Gordon Pradl acts as the second endpoint, and the object of the verb. The relation itself, “was mentored by,” is a transitive verb connecting the two people. Most relationships also have sub-types, which are included in the sentence as a participial phrase: “Sondra Perl was mentored by Gordon Pradl as a dissertation advisor.”
This grammatical structure improves, we believe, on previous academic genealogy designs in which the relations are expressed as nouns — e.g. NeuroTree’s “advisor,” “post-doc,” and so on — in part because the WST’s relationships are easily and transparently readable in reverse. The relation above, for example, could also be viewed from Pradl’s page, where it would show that “Gordon Pradl mentored Sondra Perl as a dissertation advisor”; this “reciprocal” relation is created automatically, without requiring duplicate efforts or storage. (This decision to require reciprocity had consequences, discussed after Table 1 below, for the kinds of relationships we allow for in the data structure.) In addition, the transitive verbs clarify the primary direction of influence for otherwise ambiguous terms such as “consulted,” even as we recognize that mentoring is often a two-way street.
For relationships that are explicitly collaborative and non-hierarchical, we include a category of relations using the verb phrase “Worked Alongside.”
- * indicates that the specific subtype is planned, but not yet implemented on the live site
- ** indicates that the full type is not yet implemented
Node Types
- Person
- School / Institution
- Non-School Institution4In the absence of a separate node type for Non-School Institutions, some contributors have simply adopted the School/Institution node type. See, e.g., the entry for Kairos. Relations to such nodes will be translated onto a corresponding node of the new type when it is implemented. (e.g. journal, committee) **
Relation Types
- Mentored (person-person, directed, reversible to Was Mentored By)
- as dissertation chair
- as a non-chair member of the dissertation committee
- as a writing program administrator
- as a writing center administrator
- as a WAC/WID administrator
- as a Writing Project site administrator
- as a professor (graduate)
- as a professor (undergraduate)
- as a teacher (secondary school) *
- as a consultant *
- as a formal advisor of a type not indicated above
- Studied At (person-institution, directed, reversible to Counts Among its Students)
- toward a doctorate *
- toward a master’s degree *
- toward an undergraduate degree *
- toward a secondary (high school) diploma *
- in a non-degree or other program *
- Worked At (person-institution or person-school, directed, reversible to Has Employed)
- as a professor (adjunct) *
- as a professor (undergraduate) *
- as a professor (graduate) *
- as an administrator *
- as other staff *
- Worked Alongside (person-person, non-directed)
- as co-editors of a journal
- as co-editors of an anthology or collection
- as co-authors of an article
- as co-authors of a book
- as co-administrators of a writing program
- as co-administrators of a writing center
- as co-administrators of a WAC/WID program
- on the development of a digital project
- as formal collaborators of a type not indicated above
- Served On (person-institution) **
- as an editor **
- as a founder **
- as a committee chair **
- as a committee member **
- in a capacity not indicated above **
When we were conceptualizing and prototyping the WST, we had a number of discussions about the types of formal relationships to build into the site’s architecture, and our current relationship types reflect the choices and compromises we made collaboratively at that time. Although there are compelling reasons to include other types of affiliations (including the biological, familial, and emotional, such as partners, friends, acquaintances, even nemeses or rivals), we ultimately did not prioritize them, not because they are unimportant, but because of the difficulty or fraught nature of verifying their occurrence and reciprocity. We continue to consider and debate the ways in which, as the project evolves, the WST can accommodate other types of influence that people value, giving a place to the complex, subjective nature of these genealogies while maintaining verifiable data.
Multiple Views of the Same Data
Because this data has many potential uses, it is important to allow multiple vantage points on the same data, at multiple scales. In this way, we work to avoid the trap that Alexander Galloway (2011) describes as ensnaring much data visualization work, that “only one visualization has ever been made of an information network”: the hub-and-spoke model (p. 90). We would add, however, that even in the case of a hub-and-spoke model—which we do include, as our Full Network view—distinctions can be drawn between instances of the graph that look similar at first glance. To say that all network graphs plot a center and a periphery, and therefore are all the same, is to ignore the question of content: the question of which nodes are more central, or more connected, and which are more peripheral. Connectedness communicates; centrality has consequences. At the same time, since “[d]ata are rhetorically determined entities, as are their representations” (Tirrell, 2012), we are aware that the process of capturing and visualizing these relationships into usable information in the WST is partial and subjective. The WST thus invites users to map the connections across the full discipline and also to re-center the view from many individual vantages.
Currently, the WST features three visualizations for grasping these partial views: the Individual view, the Family Tree view, and the Full Network view.
Individual View
The Individual view includes a photo (or avatar), optional brief description of research interests, searchable keywords and professional memberships, as well as lists of that individual’s connections as represented in groups of relationship types: i.e: “Has studied at,” “Has been mentored by,” etc. (See Table 1.) It also contains anecdotes and descriptions entered using the open text fields we have incorporated into each data-entry form. This feature, added in response to requests from well-established scholars, addresses the crucial need to compile histories in a centralized location, especially now that the first generation of scholars in the modern discipline of writing studies has largely passed on, and the second generation is in or approaching retirement. Linking these stories to structured data in the WST makes them more discoverable, and any registered user may add on to what they find in our database.
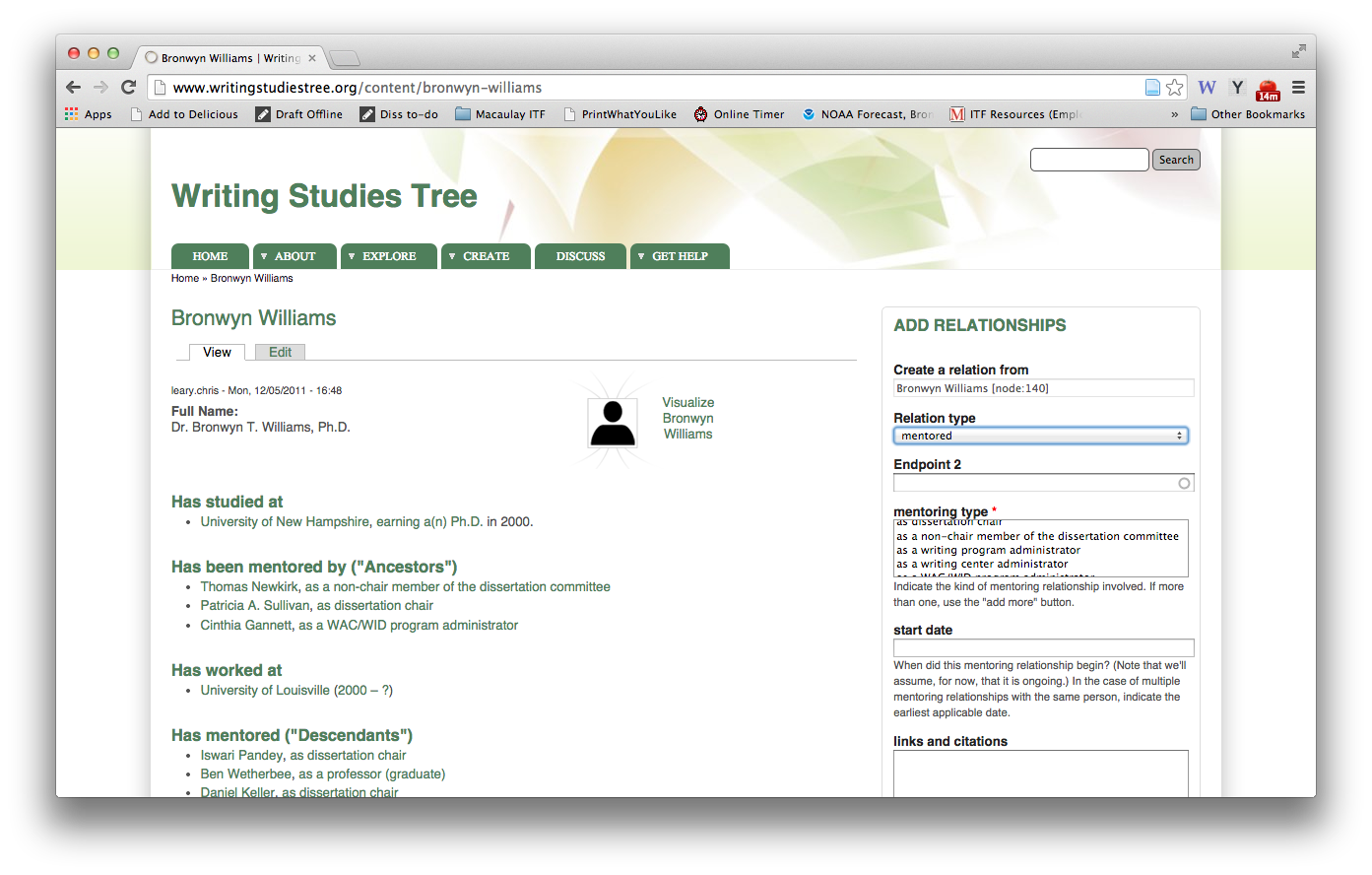
As shown in Figure 5, the Individual View also contains the Add Relationship box, a tool for linking the Person, School, or Institution shown to other nodes in the database, along any of the enabled relation types.
Family Tree View
Each person’s Individual view includes a link to a Family Tree view, showing newcomers and disciplinary leaders alike that they are part of an interconnected family. The view centers on that person, with color-coded branching lines showing relation types for two “generations” forward and backward in time, as well as lateral collaborative relations. Clicking on the icon of any person displayed re-centers the Family Tree to that individual; clicking on any person’s name in the Family Tree directs the user to that person’s Individual View page.
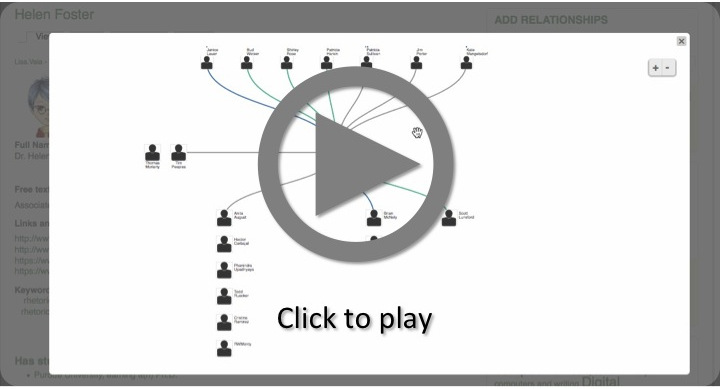
We use the family tree architecture because it is familiar and recognizable—Ancestry.com has some 8 million users—and there is value in having a visual representation that people can quickly parse. However, we also acknowledge that using a family architecture as a primary representation of our data could be seen as problematically hierarchical (cf. Weingart, 2014), especially considering the field’s recognition that “novice” and “expert” are fluid roles, contingent upon knowledge domains. One mitigating factor is that people can be “related” to people and institutions through more than one connection as relationships evolve, and that the “worked alongside” relationship type highlights the collaborative and complex nature of our field.
Full Network View
The Full Network view zooms out to show a force-directed graph of all people and institutions in the database, so that researchers can discover clusters of interconnected sub-networks. Hovering on any node for two seconds activates a Highlight view, showing that node and all others within two degrees of separation: a local “family” of people and institutions. The Full Network view also includes a Network Filter to select and highlight a subset of nodes to locate where in the graph they appear. (Users can select any combination of options from the list of people, institutions, keywords, and professional organizations.) Similar to the Family Tree view, double-clicking any node in the network opens that node’s Individual view in a new browser tab.
In our walkthroughs and Help page, we advise new users to click on the Explore tab first, which opens the Full Network view. This decision was made in order to encourage site visitors to encounter the big picture—which shifts and grows as new material is added to the database—before zooming in to specific individuals and institutions. As the network grows, this Full Network view becomes simultaneously more interesting and more complicated, with filters revealing new possibilities for research along the lines of Harris’s “Amherst School.”

Social Networking is Not Enough
In discussing the WST with our colleagues, a common response is, “Oh, so it’s a social networking site, like LinkedIn?” We understand this assumption: because both social networks and the WST are archiving details about people, they do share some features, especially in the WST Individual view. Like a profile you might find on LinkedIn, Facebook, or Academia.edu, the Individual view lists interpersonal connections, educational histories, and employment histories, making individual trajectories visible to the public.
Despite some similarities, however, neither professional nor personal social networking sites actively feature the zoomed-out perspective that links those individuals to communities and webs. Additionally, the connections that we use to build these visualizations in the WST highlight relationships that are more quantifiable and verifiable than a “friends” list. Moreover, whereas most social network sites aggressively target users with advertisements and news feeds, we deliberately avoid that kind of intrusiveness or commercialism; our goal is an academic archive that can be contributed to and queried freely. Finally, unlike most social networking sites that restrict content curation to the user’s own page, in the WST anyone can create a page for a person or institution, and likewise any user can edit this page. This trust in our users is essential for building a robust archive that aggregates information about important disciplinary contributors who may not themselves be users of the site—including founders of the field who are no longer with us.
Encourage Discovery
Though some inquiries begin with a fully articulated question or a clear gap in knowledge, many others begin with a surprise encounter or observation, as Gesa Kirsch and Liz Rohan (2008) argued in their introduction to Beyond the Archives: Research as a Lived Process. “The experiences narrated in this volume,” they write, “teach the importance of attending to facets of the research process that might easily be marginalized and rarely mentioned because they seem merely intuitive, coincidental, or serendipitous. […] Authors show how they moved from a hunch, a chance encounter, or a newly discovered family artifact to scholarly research” (p. 4). This insight continues to motivate researchers to browse physical shelves at libraries, rather than limit ourselves to online search results; it is one reason, apart from the social, that scholars attend conferences and follow each other on Twitter. We are trying to generate serendipity.
In designing the WST, we wanted to increase the chance of discovering unexpected connections, and this has manifested in three features: lists of “siblings,” folksonomic tags, and network filtering. (Users feeling particularly adventurous can also click to request a "Random Page" from the top menu bar.) Network filtering is discussed above, under Full Network view; the other two features are described below.
Siblings
One advantage of the formal relations described in Table 1 is that they can be chained together to reach beyond immediate mentoring relationships—for example, to find scholars who have shared a mentor, but may have never worked with each other directly. We call this the “sibling” relationship, and include a list of siblings on every person’s Individual View.
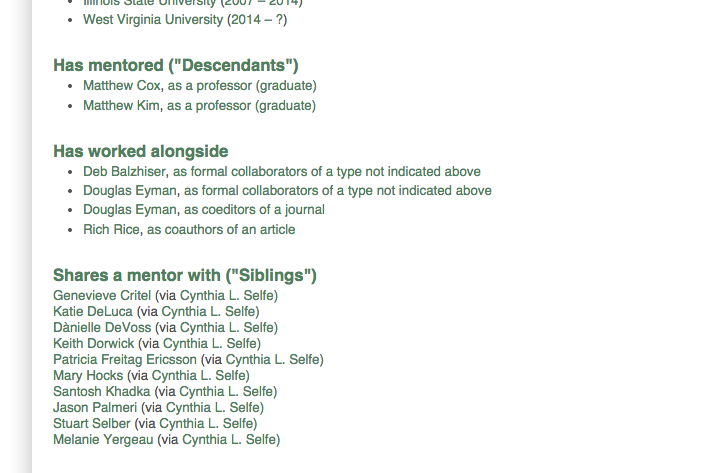
Although some siblings are discoverable by viewing a given mentor’s Family Tree, the text-based sibling list provides a more complete index, because it shows links through all mentors at once.5At present, siblings with multiple shared mentors appear as multiple lines in the list, representing the multiple relations in the database. Though we do value the increased visual emphasis this repetition provides, we hope to find more concise ways of rendering and emphasizing such overlaps. This text-based sibling list is also more accessible to blind and visually impaired users. Making large-scale data accessible to such users is a considerable challenge, given the prevalence of visualization techniques for these purposes, but it is an important undertaking, and one we will continue to address as we move forward.
Tags
Given the formal data structures elsewhere in the site design, we felt it was important to include a folksnonomic (i.e. user-provided, open-vocabulary) tagging system as well. Through either a sidebar widget on an existing page, or when editing/adding a new node, users can add any number of labels by which that page can then be indexed. We have divided this into two input fields: “keywords” and “professional organizations.” To improve autocompletion, we have pre-populated the professional organizations field with the vocabulary included in CompPile (e.g. CCCC, CWPA, IWCA), but we have also enabled users to add organizations that are not currently available in this pre-populated dataset. The keywords field is entirely crowdsourced in an effort to discover the ways that members of the field describe their own work. Registered users of the site can add either old or new terms (and therefore offer new ways to conceptualize our fields and subfields) by typing them, one at a time, and clicking “Add.”
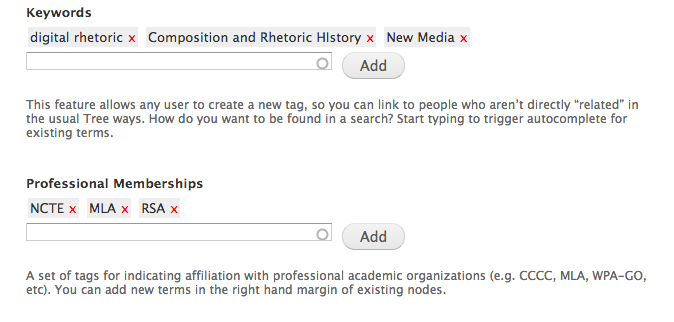
The benefits of this tagging feature are two-fold. First, it results in increased usability and more varied and informative data visualizations within the WST, such as keyword filtering in the Full Network view or tag clouds that provide a quick overview of popular areas of study.

In the tag cloud shown in Figure 10, for instance, we can quickly see that there has been wide adoption of the community tagging feature for those associated with “New Media,” “Digital Humanities,” “digital rhetoric,” and “technical communication”—perhaps because these are subfields that make wide use of keyword tagging in their day-to-day work.
Second, tags allow previously non-related people and institutions to be united under common headings. Bryan Alexander (2008) defines this interactivity in online spaces as “social filtering,” a process “leading to multiple-authored works, whose authorship grows over time” (p.153). Because those doing the tagging are most often themselves nodes in the network, this user-created taxonomy allows people to collaboratively curate their own representations in the WST, make public the language of our discipline, and discover other scholars working in similar areas for potential collaboration.
| 1. | ↑ | We welcome feedback and value your input: If you have suggestions for features or are interested in helping us further develop the site, please contact us at admin@writingstudiestree.org. |
| 2. | ↑ | Our first step was to create a screencapture walkthrough of the demonstration and guidance we would otherwise give in person, available through the Help page of the WST site. |
| 3. | ↑ | A recent source of inward links to WST entries comes from the Kairos ScholarNames wiki, and we hope to provide corresponding links back to the wiki in the near future. |
| 4. | ↑ | In the absence of a separate node type for Non-School Institutions, some contributors have simply adopted the School/Institution node type. See, e.g., the entry for Kairos. Relations to such nodes will be translated onto a corresponding node of the new type when it is implemented. |
| 5. | ↑ | At present, siblings with multiple shared mentors appear as multiple lines in the list, representing the multiple relations in the database. Though we do value the increased visual emphasis this repetition provides, we hope to find more concise ways of rendering and emphasizing such overlaps in the future. |